问题的现象:
1,每个整点前后,集群会出现少量的4xx和5xx请求.
2,每个整点前后,集群的所有下游请求(codis,mysql)耗时 都会有比较小的抖动.
3,每个整点前后,当前集群的上游集群也会出现少量的4xx和5xx问题.
20日前后, 集群开发爆发大量的整点5xx和4xx错误.持续时间1-2分钟不等.后面会自动恢复.
开始着手排查
措施之一:扩容
20日后有明显的流量变更,开放了流量入口.
但是按照机器资源的使用情况来看,问题与故障出现在整点.所以和流量非正相关.
但是考虑到增加容量可以暂时缓解问题.并且集群容量阈值也偏低. 故申请了两台机器扩容到集群上.
问题有所缓解,但没有找到根因.没有彻底解决.
逐步排查过程:
观察集群日志和响应时间,可以确定集群在整点前后,所有下游请求和上游请求的整体耗时都有增长.
超过了能够承载的平响时长的临界值.
按照计算.集群7台机器.每机器开启512个php-CGI进程处理请求.
整体平均响应时间为15ms左右(nginx/access.log统计) .
在流量高峰的时间内,整个机器的单机平均QPS在2800左右. 如果QPS 保持不变.去计算平均响应时长的极限值情况.
1000ms/(2800/512) ≈ 180ms
得到极限的响应时长为: 180ms左右.超过这个阈值.则会导致整体CGI进程数耗尽.无法响应请求.
观察nginx的耗时统计:
如下图 :
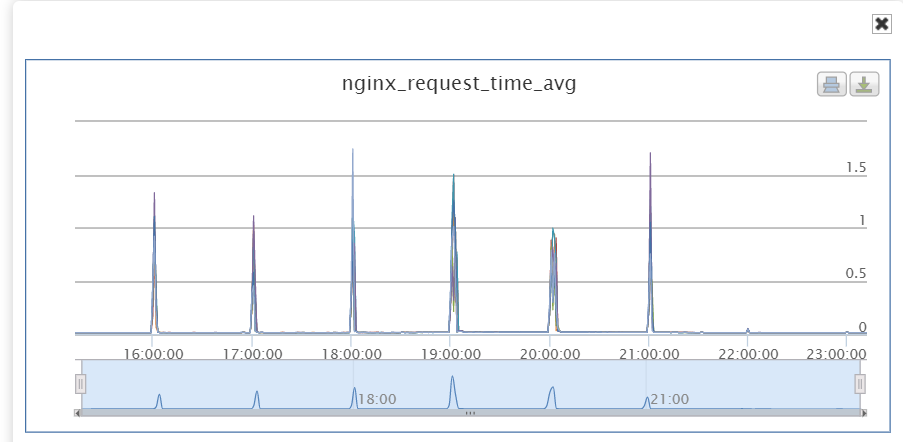
在故障期间每个整点前后nginx耗时会超过1秒 .导致整体集群超载.触发大量错误.
超载带来的附加影响:
集群超载后,会导致上游请求无法响应.进一步触发上游的重试请求.
整体集群的流量还会进一步飙升. 造成更进一步的错误.
恶性循环.
排查nginx日志 ,可以看到整点前后确实出现了 请求无法向php-fpm转发的情况.(11错误)
排查php错误日志,可见请求处理时长有明显的增长情况.(统计log里面的cost字段 )
由于集群的php阻塞 导致长期占用codis的 session 从而导致codis的session得不到释放.其他集群在连接codis的时候获取不到session 连接失败 .
从而向当前集群发起请求获取信息.
抓包其中一个cgi进程,可以明显看到accept的耗时在整点前后呈现明显的波动情况. 甚至超出了1秒.
在正常和异常之间来回抖动.
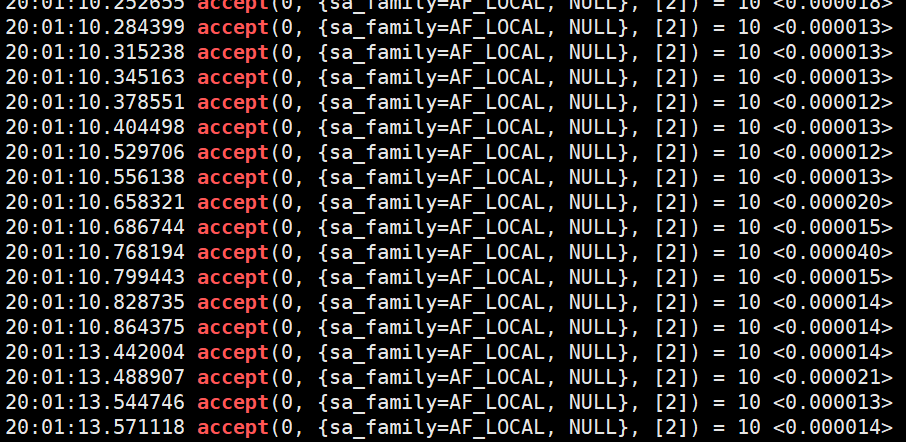
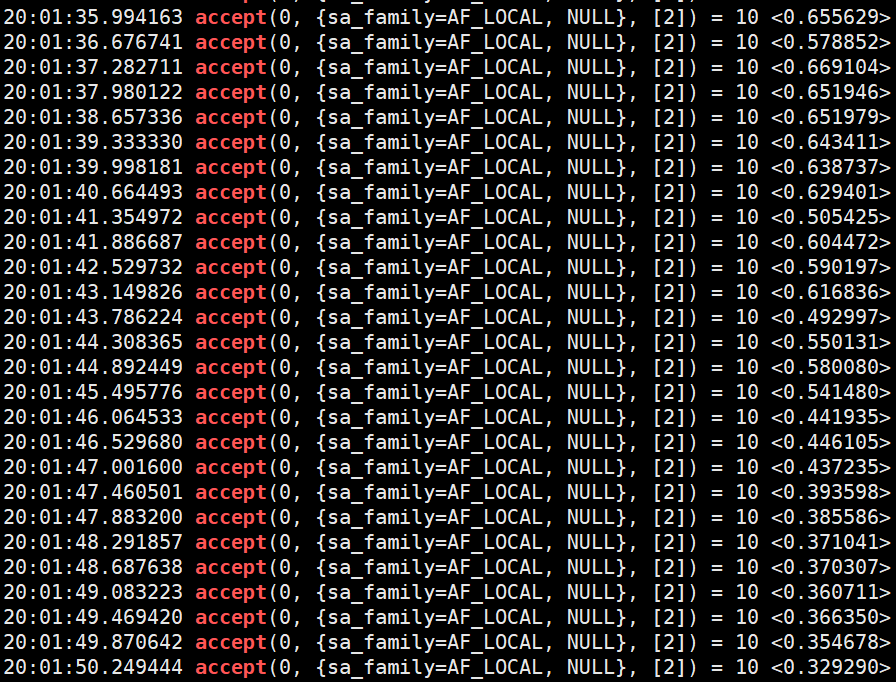
综合上面得到的所有信息,可以确定是集群整点期间的某些迷之行为导致了集群整体响应时间变长,从而进一步触发了雪崩效应.但是整点的迷之行为结束后.集群还是能够恢复正常的.
怀疑1: 和集群日志切割有关系.排查集群日志切割.
集群上面整点的日志切割分为几部分:
第一部分 nginx相关的日志切割,可以通过nginx的日志表现观察出nginx在故障期间,工作是没有问题的.
第二部分 php相关的日志切割.PHP日志量不大,而且翻找公司WIKI得到,之前切割日志的问题已经修复.
第三部分 应用目录的日志切割,这部分切割使用脚本直接mv操作. 之前脚本的BUG 已经被修复.
第四部分 ral(统一资源访问层扩展)日志切割,有单一cgi进程进行切割.不会造成问题 .
尝试关停集群上一台机器的日志切割脚本.问题没有改善.
排除掉当前机器日志切割导致的问题.
怀疑: 大数据团队拖日志导致集群IO被占用,从而导致集群出现抖动
发现其他集群也有类似的IO波动.对于万兆网口和ssd磁盘io来讲.100+M左右的IO不构成影响
排除掉.
怀疑: 下游服务的整点日志切割导致的问题codis和mysql (OP提出)
尝试将codis的日志切分向后调整十分钟,集群的抖动现象也跟着向后移动了十分钟.
问题定位;
问题进一步分析:
codis请求流量大.整体峰值QPS在25W左右. 单个小时的日志量大概为每台机器2G左右.整个日志的切割过程.会出现codis响应变慢.
codis响应变慢,间接导致集群上面的请求整体平均耗时增长.触发达到临界状态. 导致整个集群无法响应请求.
集群出现响应超时,进而触发重试.上游又有大批量的流量进来.进一步导致集群可用性下降. 进而引发其他集群一起抖动.恶性循环
日志切割完成后,codis可用性恢复,请求能够被逐渐消化掉.恢复正常.
[OP的排查]
根据现在的排查大概推论一下
1. 4.20日业务变更,某接口流量上涨5倍,每秒1k+的qps。
实际上涨1倍请求量. 集群整体流量上涨20%左右, 之所以峰值过高是因为整点触发的重试请求
2. 整个集群的php-fpm数和qps数基本到了一个临界值。
这一条分析没问题
3. codis整点切日志是cp,可能是导致codis集群响应变慢的原因,待查
4. codis响应变慢导致集群接口响应变慢,直至php-cgi进程耗尽,业务日志上表现是先有499,耗尽之后直接502.
5. 上游依赖该集群的服务,因为整体调用链路问题,先和codis集群建链,等待接口接口返回数据后才写入codis,导致其他服务的codis集群session上涨.
改进措施:
1, 梳理集群的整体超时时间,重新根据平均响应时长调整调用超时时间 . 防止集群抖动会影响到其他集群.
2, 操作调整CODIS的日志级别,只记录异常日志,正常请求日志不再进行记录.
后续事项
集群的上下游依赖导致的集群抖动不仅仅出现在当前一个集群上面,目前从观察上看,其他集群也存在类似现象. 所以有必要进一步进行排查.
当前集群体现的更明显,是因为当前集群的CODIS流量相比其他集群都要大很多 .目前来看,当前codis集群的整体流量是平台的No1.